
Kubernetesを使ってアプリケーションを運用していると、次のようなニーズが生まれます。
- PodやNodeのリソース使用量(CPUやメモリ)をグラフで見たい
- 障害の予兆を検知したい
- システム全体の健全性をダッシュボードで可視化したい
これらを実現するための王道の組み合わせが、**Prometheus(プロメテウス) + Grafana(グラファナ)**です。
✅ Prometheus とは?
Prometheus は、メトリクス(数値データ)を収集・保存・クエリできる監視ツールです。
特徴:
- Kubernetesに特化した監視が可能
- Node・Pod・Containerのメトリクスを自動で収集できる
- 「Pull型」でメトリクスを取得(Exporterから定期的に取得)
✅ Grafana とは?
Grafana は、Prometheus などのデータソースから取得した数値データをグラフ化・ダッシュボード化するツールです。
特徴:
- WebブラウザでアクセスできるUI
- 美しいダッシュボードをGUIで構築可能
- アラート通知も設定できる
🧩 Prometheus + Grafana のアーキテクチャ
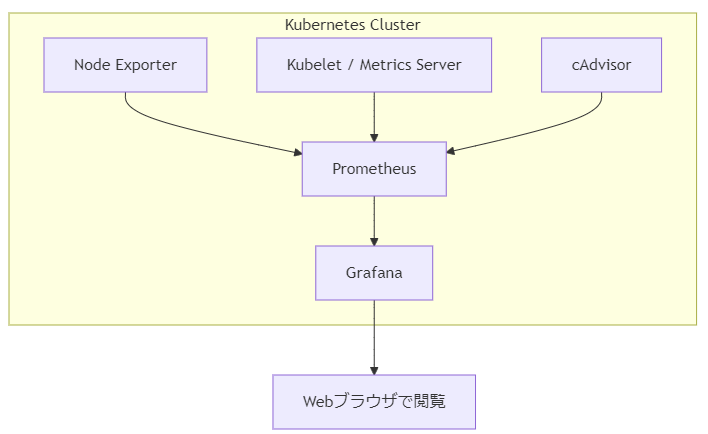
Prometheusが各NodeやPodからメトリクスを集めて保存し、Grafanaがそれをグラフ表示します。
🚀 実際の導入方法(例:Minikube環境)
1. Prometheus と Grafana のインストール(Helm利用)
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install monitoring prometheus-community/kube-prometheus-stackこの1コマンドで、以下が一括で導入されます:
- Prometheus(本体+Alertmanager)
- Grafana
- Node Exporter
- kube-state-metrics など
2. Grafana にアクセス
Grafana Podが起動したら、ポートフォワードでアクセスできます:
kubectl port-forward svc/monitoring-grafana 3000:80→ http://localhost:3000 にアクセス
初期ユーザー名・パスワードは admin / prom-operator(※変わることもある)
3. ダッシュボードの表示
Grafanaにはあらかじめ「Kubernetesクラスタ用のダッシュボード」が用意されています。NodeのCPU使用率、Podのメモリ使用量、リクエスト数などがグラフ化されます。
💡 補足:主要なメトリクス
| メトリクス名 | 説明 |
|---|---|
node_cpu_seconds_total | CPU使用時間(Node単位) |
container_memory_usage_bytes | コンテナのメモリ使用量 |
kube_pod_container_status_ready | コンテナの起動状態 |
kube_deployment_status_replicas_available | Deploymentの稼働レプリカ数 |
これらを使って、アラート条件も設定できます。
📌 まとめ
| ツール | 役割 |
|---|---|
| Prometheus | メトリクスの収集・保存・クエリ |
| Grafana | メトリクスの可視化・アラート |
Prometheus + Grafana は、Kubernetesのモニタリングでは定番の組み合わせです。導入のハードルは少し高いように感じるかもしれませんが、Helmを使えば簡単に始められます。
慣れてくれば「アプリごとのレスポンスタイム」や「エラー率」なども可視化できるようになります。